The short version (executive summary):
Agent Gateway is CA product formerly known as Secure Proxy Server, for the purpose of this article, I'll refer to it as Agent Gateway or Ag for short.
When one back-end sever for Agent Gateway goes down, all of the connections pool entries and worker threads are clogged up with transactions for the one down (or v slow) "bad" back-end server. Other requests destined for other "good" working back-end are also held up and do not get processed. The effect is the one "bad" back-end server tends to drive the whole Agent Gateway offline and it is unable to process any requests.
The solution is: to give a fixed max size to the back-end connection pool; the fixed max size has to be less than the max available worker threads; and to give a quick timeout for any request trying to get a back-end connection beyond that thread pool size. Then when one back-end server fails, it does hog worker threads, but only up to the limit of the connection pool size, and importantly it leaves the remaining threads free to handle requests to non-hung backend servers.
The settings to change server.conf are from:
# http_connection_pool_max_size="420"
# http_connection_pool_wait_timeout="0"
to:
http_connection_pool_max_size="100" # (max pool of 100)
http_connection_pool_wait_timeout="200" # (timeout if pool size already over 100 of 200ms)
The longer version :
1. Background.
Because Agent Gateway acts as a proxy, is holds onto the connection from the front end (client) while it sends the request to the back-end server to be processed. For a working back-end system the response time is generally fairly quick and the number of connections/worker threads needed to maintain throughput is minimal.
So for example, as in the diagram below:

If we have requirement for 100 request/sec, and the back-end response time is 200ms, then the bandwidth in connection/threads we will need is to be able to handle about 20 requests in parallel. So we will need: 20 httpd worker threads in apache; 20 connections via mod_jk from apache to tomcat; 20 worker threads in tomcat; and 20 connections to the back-end server. Note the SPS is mostly not doing any activity, rather of the elapsed 200ms most of the time the threads are inactive waiting for the response from the back-end server.
However if the back-end sever performance slows down, so rather than 200ms each transaction takes 2sec, Then the amount of in-progress transactions that Ag will have open at one time will increase. That would be 100 trans/sec x 2sec = 200 open transactions. So now we need a bandwidth of: 200 connection pool sizes; 200 thread pool size etc, for each component. Obviously if the back-end server goes even slower then the pool/thread sizes requirements continue to increase.

Ultimately if we get to a stage where the back-end server is down, then for the original 200 request/sec load, then (with the default settings, of a 60sec timeout and a 3x retry) we are faced with each transaction taking 180sec before it sends it's failure response back to the client.
Under those conditions the connection/thread pools sizes that we would need is 18,000. So we would need: 18,000 httpd threads; 18,000 connections from clients to httpd; from apache via mod_jk to tomcat, tomcat threads and from tomcat to the back-end.
Obviously before that we've probably hit some limit, probably a 150 thread pool size in apache, or 600 or 1000 depending on what you have it set to. But the important thing is when the back-end server is down, the SPS is flooded with waiting requests, and we can't realistically (or meaningfully) hold open all of those requests for all of those retries.
But this is not the problem we are solving - this is the background to the problem.
2. The Problem - one bad back-end can stop all activity

Now, generally an Agent Gateway server has multiple back-end servers. And if one back-end servers goes down then as we've seen that leaves a heavy footprint on the internal Ag infrastructure, blocking up all the pipes, and stopping acces to all back-end servers, not just the non-working server.
3. Connection Pool Size
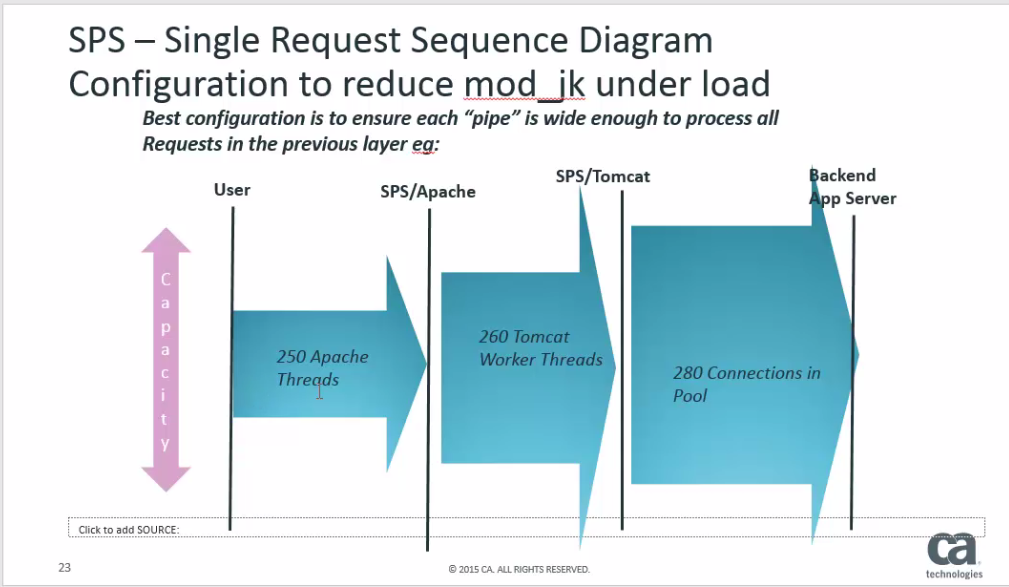
Here is the pattern of connection/thread pool sizes that is best for throughput if the Agent Gateway has only one back-end server. The design is that at each stage the next pipe bandwidth is slightly larger than the previous one. With that model all incoming requests will be forwarded onto the next stage, and ultimately onto the back-end server, there will be no internal bottleneck within Ag.
The reality is for Ag that in normal operating conditions the default connection pools are low, often only 5 or 10 or 20 active requests, depending on the type of transaction, and that the pool sizes & thread counts only go up to values of 100 or more when there are delay or problems with the back-end servers.
4. The Solution
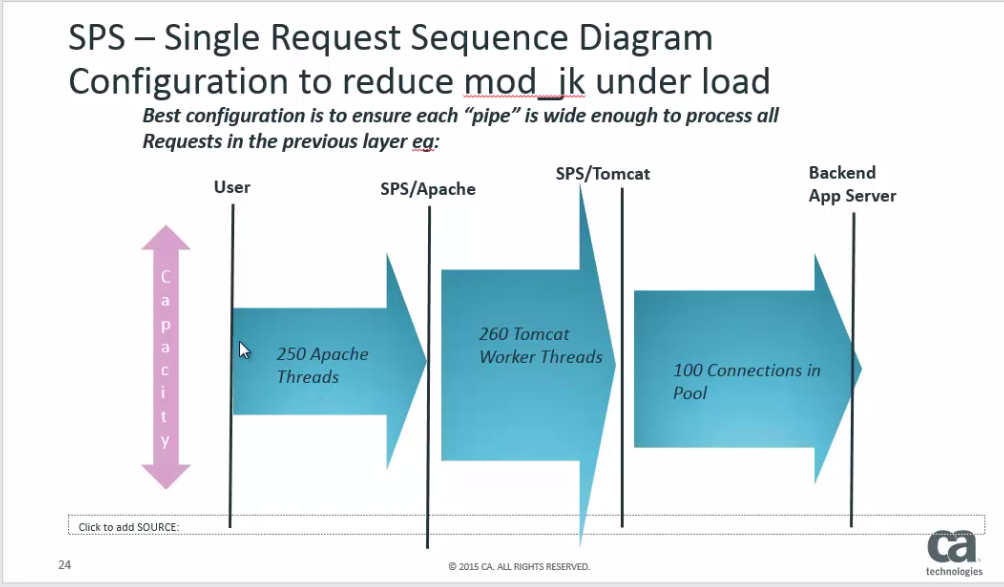
If we have multiple back-end servers, and we know :
a) That normally the pools size is about 20 connections; and
b) That if the back-end connections go above 100 we know there is a problem with that back-end server.
Then we can setup the back-end connection pool as above, where there are less connections to the back-end than there are httpd & tomcat worker threads.
Normally if we have a connection pool of 100, and all 100 get used, then when the 101'st request come in for the same back-end, then the new request/thread would wait (forever) for a connection to become available.
But for our purposes, we know that since we already have 100 requests in progress, that we are in trouble, so what we will do is add a quick timeout, so this new request will timeout very quickly return an error to the client, and importantly it will return the httpd & tomcat worker threads back into the available pools.
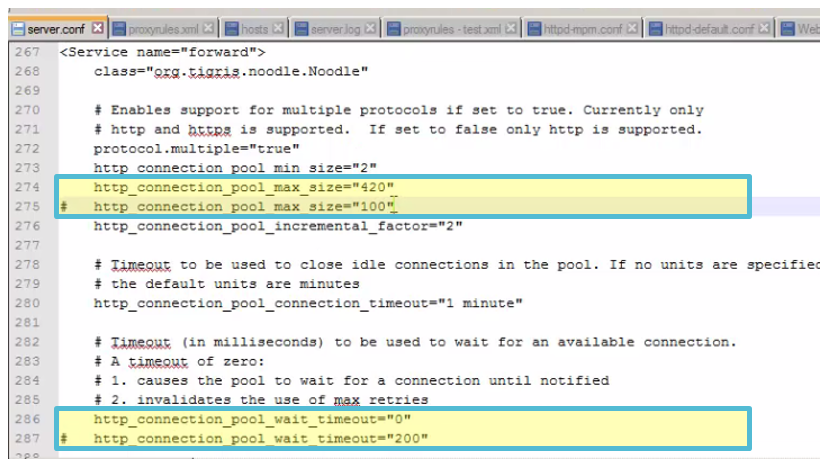
Here are the settings we change in server.conf :
http_connection_pool_max_size="420"
http_connection_pool_wait_timeout="0"
And we change them to :
http_connection_pool_max_size="100" (max pool of 100)
http_connection_pool_wait_timeout="200" (timeout over 100 of 200ms)
So when we have one "bad" back-end server, it will have 100 threads waiting on a response or connection to the backend, But importantly only 100 worker threads. The remaining ~150 httpd worker threads, and tomcat worker threads are still free to handle requests for "good" back-end servers. And so the requests for the "good" servers are still processed as normal. The 100 or so waiting threads are not using a lot of resources, as they will be mostly idle waiting for a response from the "bad" back-end server, so thoughput to the good servers does not seem to be affected much.
5. The Video - Testing the Solution
We also ran some sample test jmeter scripts using this technique, the results jmeter script & recorded video are in a second post, at the following link :
TechTip: Testing Solution to Agent Gateway/SPS with one bad back-end
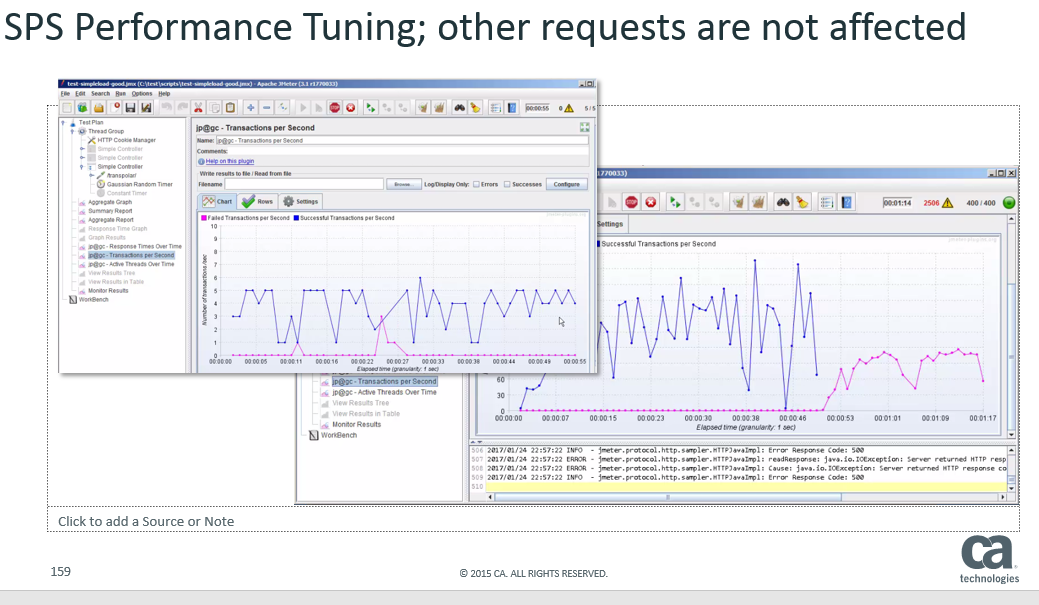
Effectively, the results are that if we have the original, and most common configuration then as expected when one backend server goes down, the traffic to the other backend servers are affected as well. Below the blue shows successful transactions, and the pink errors. We can see that both servers are affected :
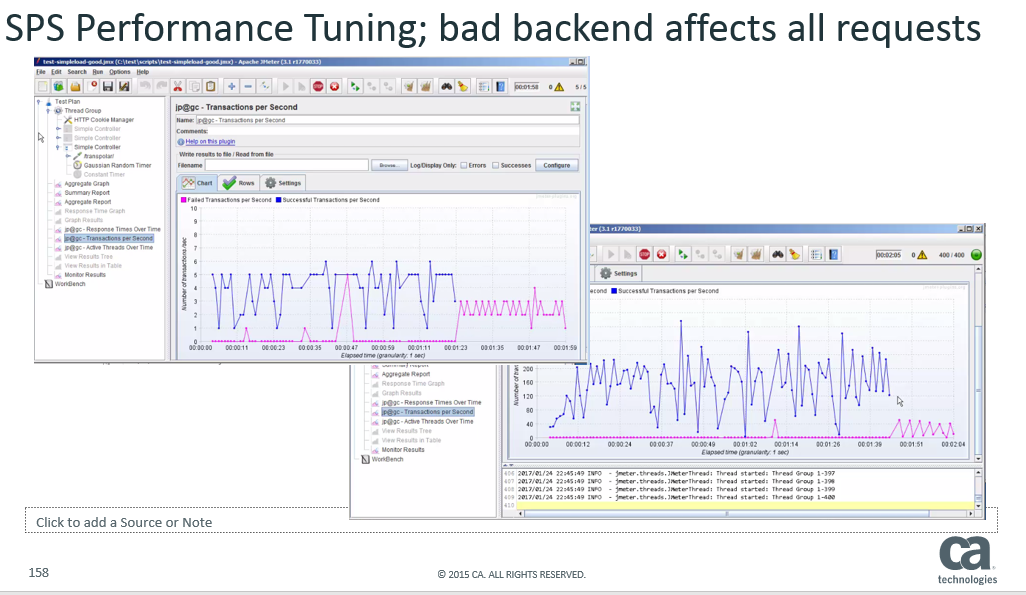
However, with the settings are we suggest above, when one backend server goes down, traffic to the other backend server is essentially unaffected:
6. Conclusion
Traffic and load are always different for different installations. The best way to ensure your Agent Gateway is configured to both handle your normal traffic load & load under exceptional circumstances is by testing. With the load testing It is best to also test to breaking point to understand where & how the system breaks. And also how the system performs when components - such as the various back-end servers - fail.
The above offers a way to handle the common situation where one back-end server goes down, we recommend that you test the setting in your own QA environment, both with normal conditions and its response with failed back-end servers before applying them to production.