Team,
While working with clients, both Amit Sinha sinam09 & I were reviewing the Identity Suite J2EE/Wildfly cluster configuration using the hornetq process.
Hornetq provides two (2) types of clustering: symmetric and chain. Both provide reliability for SPOF (single point of failure). Chain configuration requires minimal configuration; and lowers traffic between the # of cluster nodes.
HornetQ User Manual

From analysis of the Identity Manager in a five (5) node cluster, we have created rules to assist with setup & validation of a cluster larger than two (2) nodes.
Rules:
1) Of the possible configuration, we selected Uni-Cast (TCP) over Multi-Cast (UDP) to avoid forcing all nodes to be on the same subnet. This allows cluster nodes to reside on different network segments or even across a WAN (be aware of latency challenges due to global distances).
2) Of the two (2) configuration to share data, between File Replication & Shared Storage, we chose "File Replication" to avoid the dependency and need to have a common NFS/SMB/other shared location between all the nodes. We also wish to avoid any possible lock file concerns.
3) When setting up a cluster, declare one of the nodes to be master, for the "standalone-full-ha-xml" file. This file will be 99% the same for all cluster nodes. This will help eliminate challenges due to incorrect formats between nodes. This "master" file, with all of it's data sources pre-defined with hashed passwords, and any other updates will be copied to the remaining "cluster nodes".
4) Before starting the other nodes,
a) Three (3) updates will be done within the JBOSS_HOME/bin/standalone.sh file for each node/server of the cluster.
JGROUPS_BIND_ADDRESS="172.31.56.155"
NODE_NAME="iamnode1"
BIND_ADDRESS="172.31.56.155"
or be clever and use the ability to "run an executable command" in the shell script, e.g. `hostname` or `hostname -I`
- This will allow the "standalone.sh" file to be exactly the same between all cluster nodes.
JGROUPS_BIND_ADDRESS=`hostname -I`
NODE_NAME=`hostname -I`
BIND_ADDRESS=`hostname -I`
Note: This assumes that the other variables, in standalone.sh, have the same values.
Example: Shared Settings: Define the other cluster members’ host names & the unicast port. [All other values should be the same, just pulled these out to clarify.]
JGROUPS_INITIAL_HOSTS="caim-srv-01[7600],caim-srv-02[7600],caim-srv-03[7600],caim-srv-04[7600],caim-srv-05[7600]"
MULTI_CAST_ADDRESS="231.0.0.5"
STANDALONE_CONFIGURATION="ca-standalone-full-ha.xml"
b) Six (6) updates will be done within the JBOSS_HOME/standalone/configuration/standalone-full-ha.xml file for each node/server of the cluster.
Chain cluster implies that each server is in a chain from a prior one to another one.
[LIVE SECTION]
<hornetq-server>
<persistence-enabled>true</persistence-enabled>
<shared-store>true</shared-store> [This is the confusing part, while this implies that a share storage is required, if the other values do not reference a remote storage location, then file-replication will be used.]
<backup-group-name>node1</backup-group-name> [unique name for each node1, use the defaults of “node1”, “node2”, “node3”, etc.
<broadcast-groups>
<broadcast-group name="bg-group1"> [aka “LIVE” broadcast group]
<jgroups-stack>tcp</jgroups-stack>
<jgroups-channel>live</jgroups-channel>
<broadcast-group name="bg-group2">
<jgroups-stack>tcp</jgroups-stack>
<jgroups-channel>node1_live_to_node2_backup</jgroups-channel> [Note this format; it is important!!!.. nodeN_live_to_node(N+1)_backup ]
<discovery-groups>
<discovery-group name="dg-group1">
<jgroups-stack>tcp</jgroups-stack>
<jgroups-channel>live</jgroups-channel>
</discovery-group>
<discovery-group name="dg-group2">
<jgroups-stack>tcp</jgroups-stack>
<jgroups-channel>node1_live_to_node2_backup</jgroups-channel> [SAME format as above for “LIVE” configuration]
[BACKUP SECTION]
<hornetq-server name="backup">
<clustered>true</clustered>
<shared-store>true</shared-store>
<backup-group-name>node2</backup-group-name> [This name will be the “next” node in the chain, keep this naming format]
<broadcast-groups>
<broadcast-group name="bg-group1">
<jgroups-stack>tcp</jgroups-stack>
<jgroups-channel>node5_live_to_node1_backup</jgroups-channel> [Note this format; it is important!!!.. node(N-1)_live_to_node(N)_backup ]
<discovery-groups>
<discovery-group name="dg-group1">
<jgroups-stack>tcp</jgroups-stack>
<jgroups-channel>node5_live_to_node1_backup</jgroups-channel> [Note this format; it is important!!!.. node(N-1)_live_to_node(N)_backup ]
#### If the node is the last node, then it MUST be the prior chain “node” for node1. So for five (5) nodes, you would use node5, for three (3) nodes, you would use node3; when updating the standalone-full-ha.xml for node1 ####
5) Validate the cluster by monitoring the following:
a) Monitor the J2EE server.log / wildfly.log for any hornetq error messages [expect to see start/shut down message but no others]
b) Use the jboss-cli.sh process to monitor the JMS queue
Useful Wildfly/JBOSS CLI Monitoring Scripts
c) Exercise a use-case update within the IM User Console, with two (2) browser windows
i. Within the first browser, update an IM Admin Role description
ii. Within the 2nd browser, view the IM Admin Role to see if the description update can be seen.
(If the cluster is setup correctly, then the 1st Wildfly serer would have sent a JMS message to the 2nd Wildfly server to tell it, to refresh itself from the IM objectstore. If the cluster is NOT setup correctly, then the description will not have appeared to change. ]
Cheers,
Alan & Amit sinam09
Edit: 4/11/2018 Delta view of the two (2) files using open source WinMerge (for both standalone.sh & standalone-full-ha.xml). WinMerge
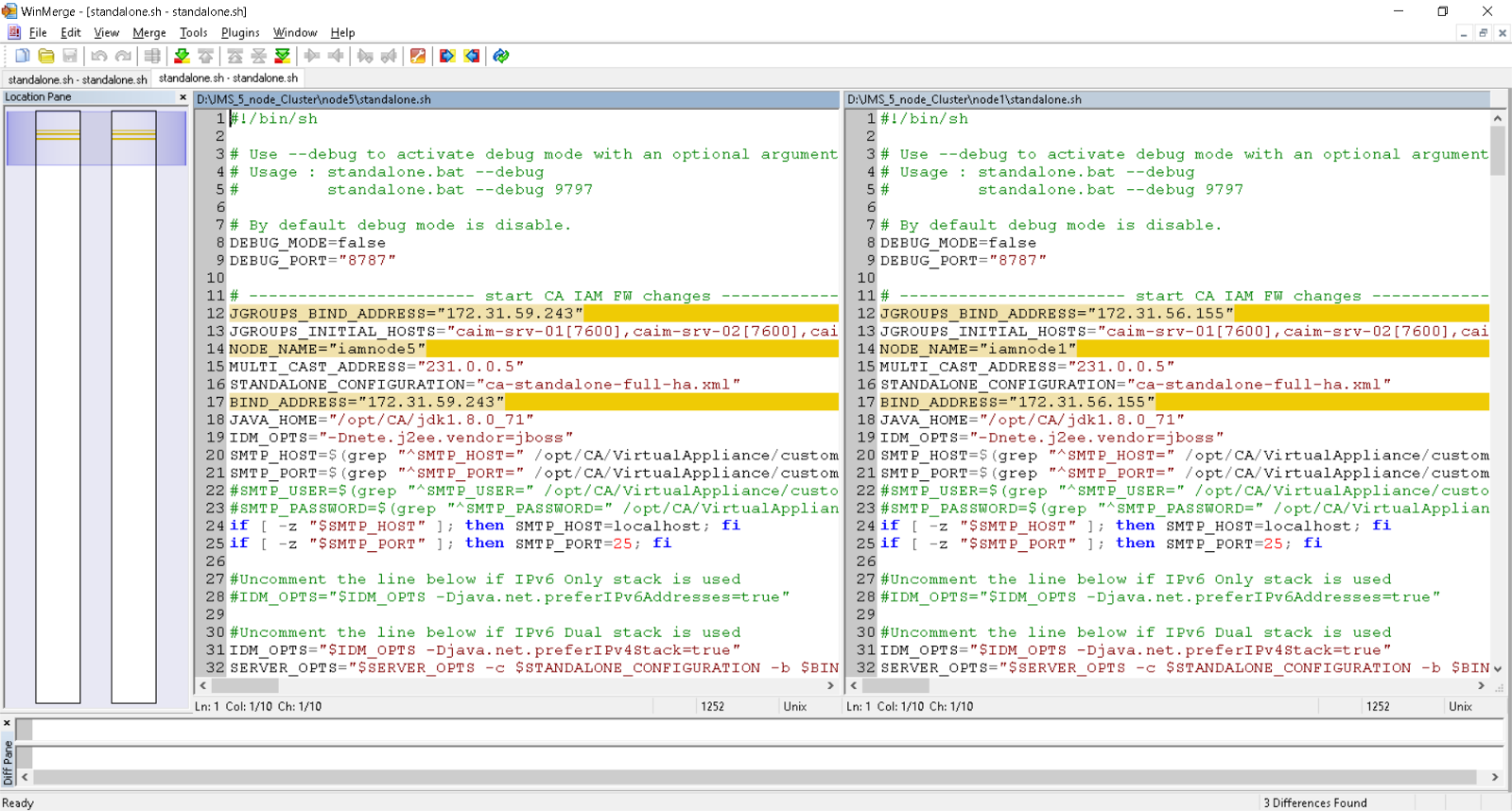
Standalone.sh delta between node1 and node2
Note: Three (3) deltas ONLY.
Note2: May be zero (0) deltas if using the executable command `hostname -I` for the three (3) lines.
Standalone.sh delta between node 5 and node 1
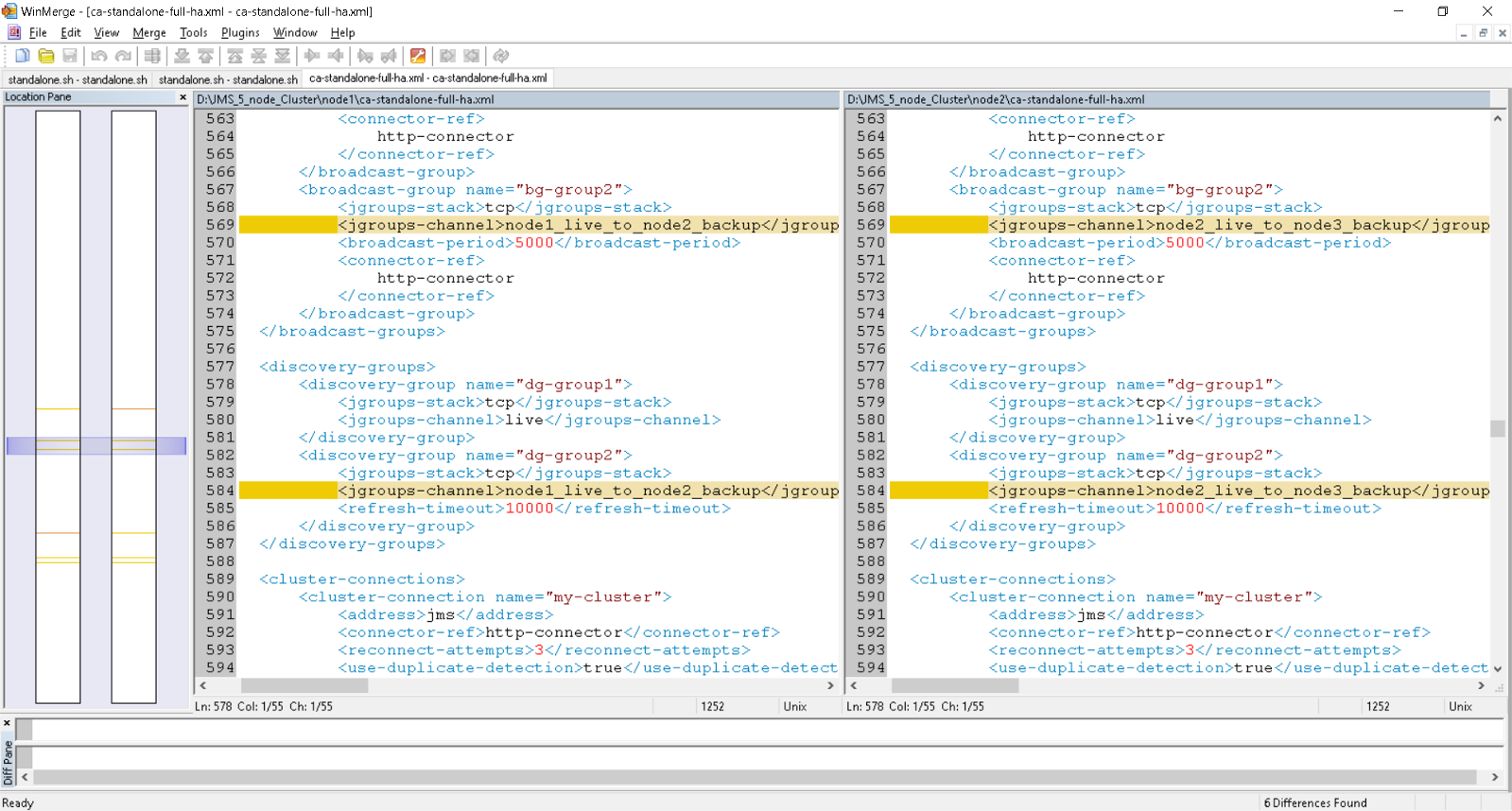
standalone-full-ha.xml [ca-standalone-full-ha.xml] delta between node1 and node2
Note: Six (6) Deltas ONLY



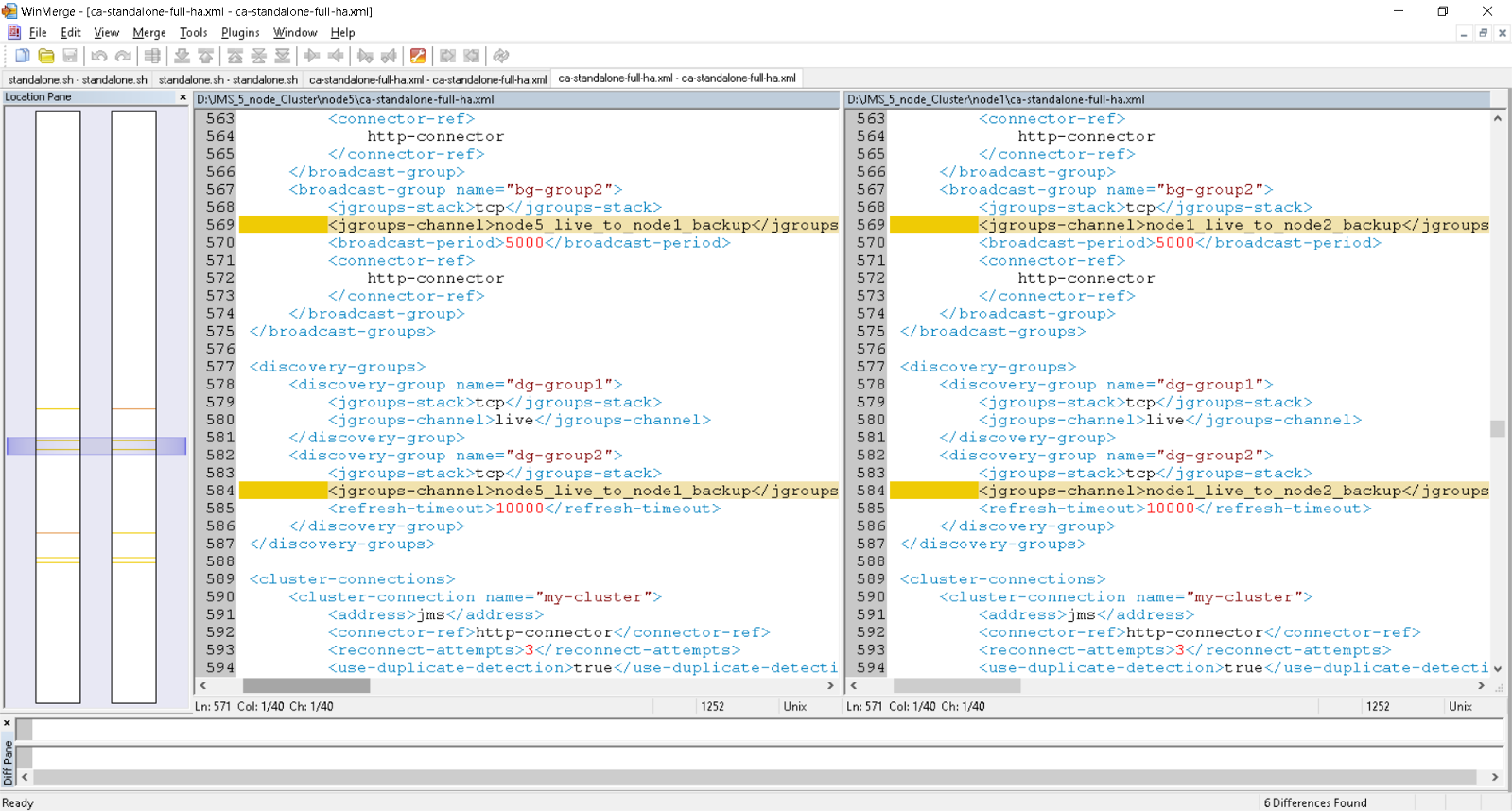
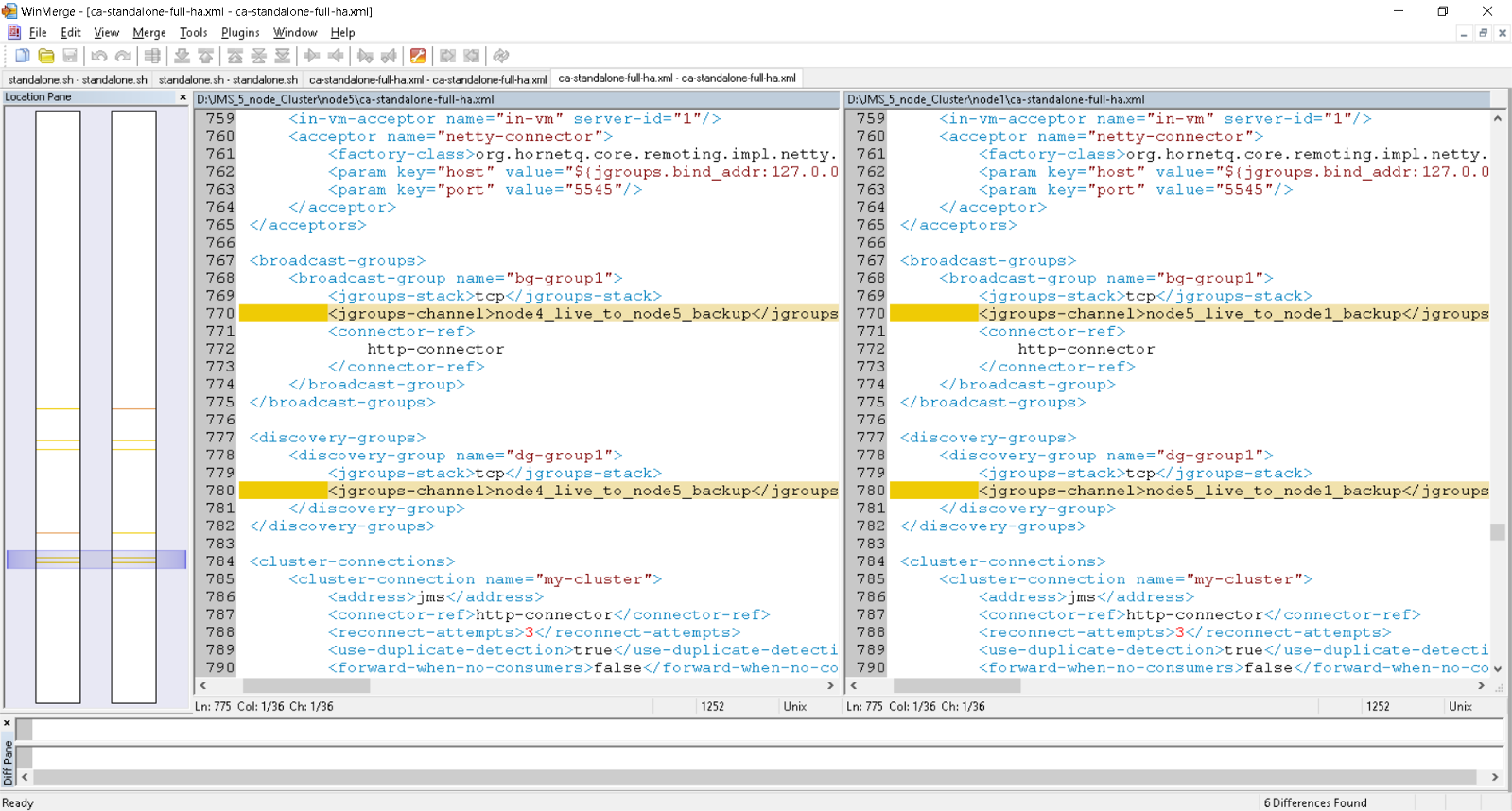
standalone-full-ha.xml [ca-standalone-full-ha.xml] delta between node5 and node1
Note: Six (6) Deltas ONLY

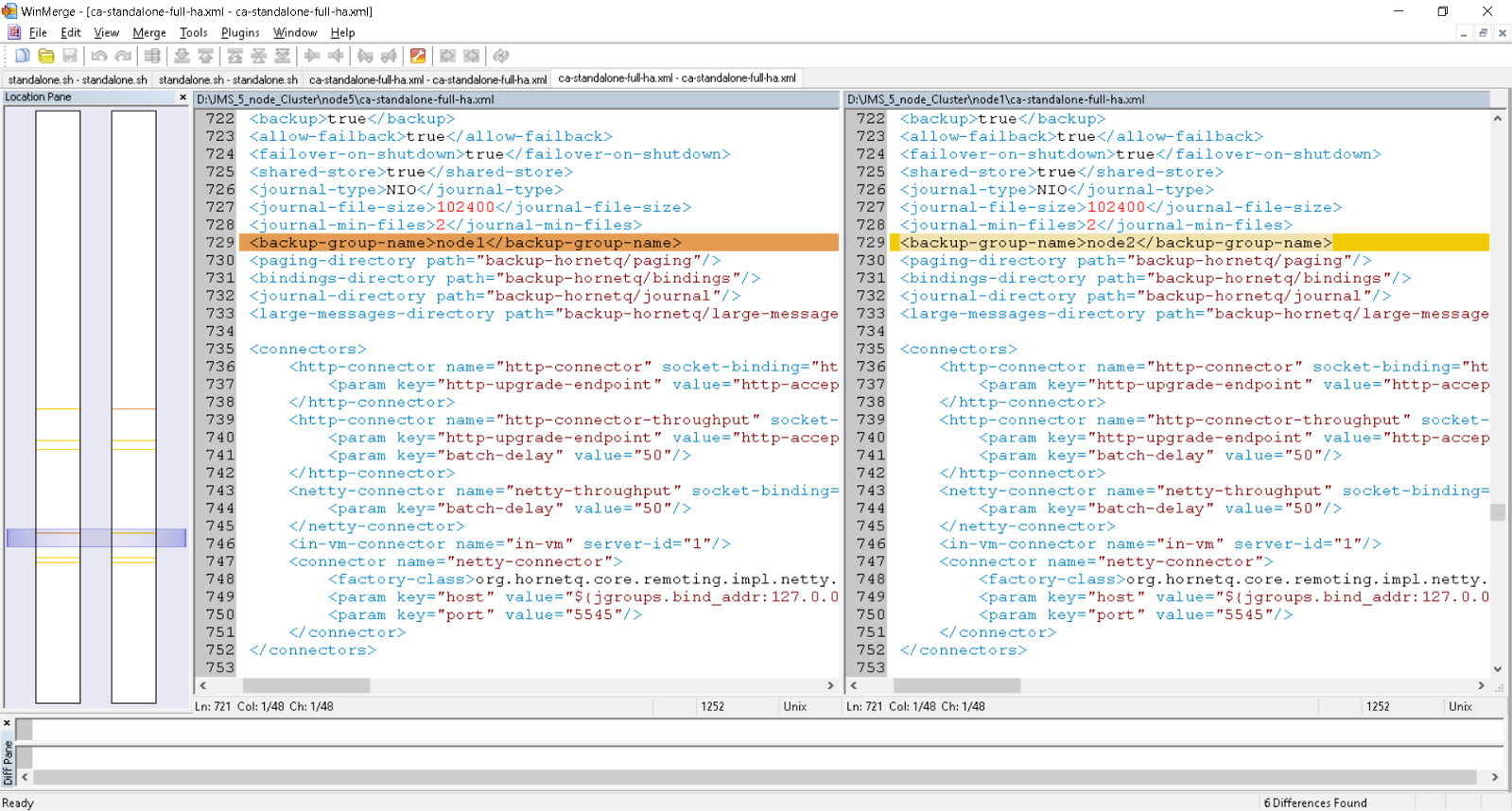
Edit: 7/24/2018 Added example of jboss-cli.sh input files for five (5) nodes; includes JMS and updates for data sources of TP/OS for the CA IM solution.