Team,
To provide a better methodology to track load balancing of the IAMCS (aka JCS) Tier, I have compiled the following steps:
1) Enable the ADS detail logging on the IMPS Manage ADS endpoint for TEXT.
- Use the IMPS GUI to set.
- This update change the following attribute: eTLog: 1 & eTLogFileSeverity: FIESW
2) On the IAMCS/CCS Server, deploy BareTail or similar tool to monitor the new TEXT file log for ADS under JCS log folder. This process will allow us to get useful detail debug logs, but not require us to enable full verbose logging under the JCS tier.
3) On the IMPS Server, may be on Linux for vApp, use SSH client tool (putty/MobaXterm) to connect and su to imps user: su - imps
- Change folder to logs.
- Issue a ls command to identify the recent etatrans*.log file: ls -lart
- issue a tail command with a grep for the Load Balancing key phrase.
tail -f etatrans20181120-1903.log | grep -A 1 "Load Balancing"
- Use the -A option to view the complete string with all JCS servers.
- If ANY JCS has a metric of 999.00; then that JCS will NOT be used by the IMPS Server.

4) Now execute your bulk loads or other processes to test the load-balancing features.
For my testing, I used the CA Directory test tool, dxsoak, to push the system to 20 threads of updates to an ADS account. su - dsa then change folder to samples/dxsoak to run the below example.
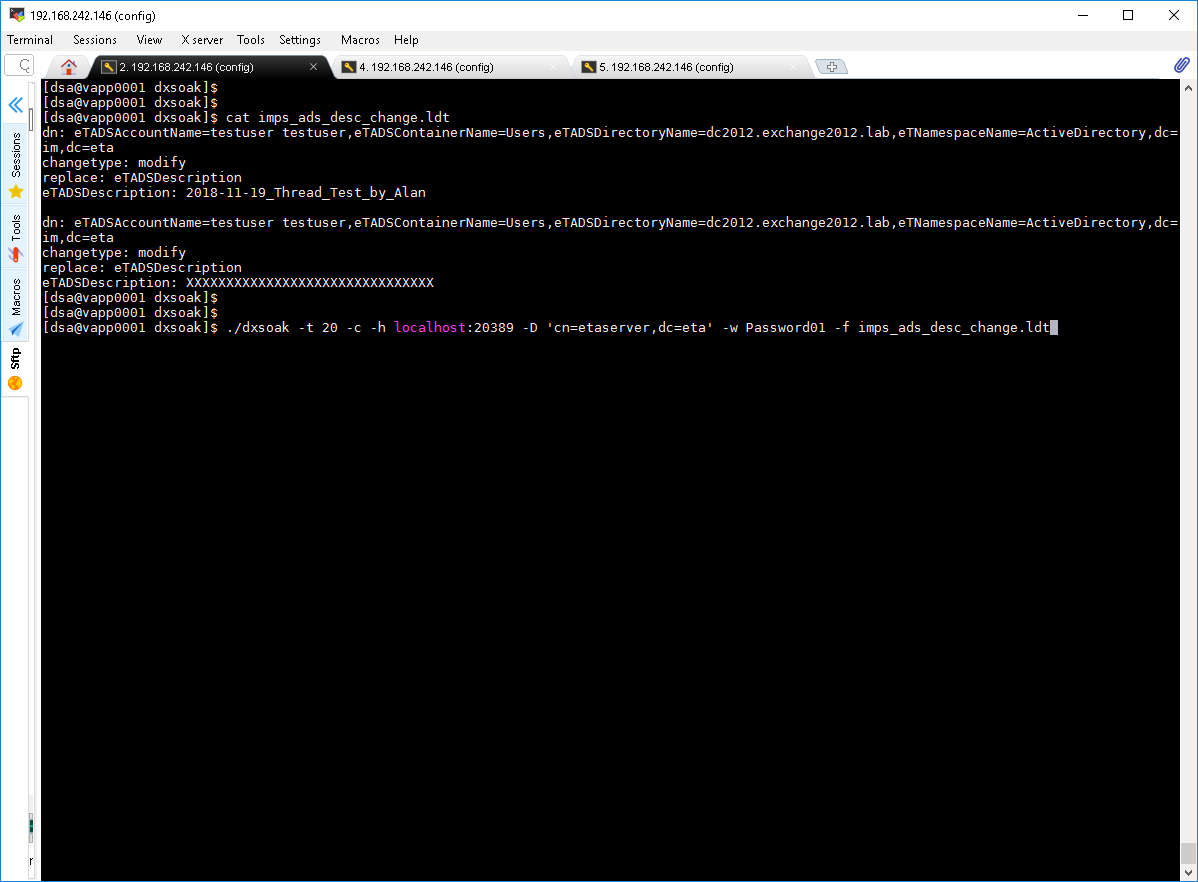
./dxsoak -t 20 -c -h localhost:20389 -D 'cn=etaserver,dc=eta' -w Password01 -f imps_ads_desc_change.ldt
############################## DXSOAK INPUT FILE BELOW ########################
dn: eTADSAccountName=testuser testuser,eTADSContainerName=Users,eTADSDirectoryName=dc2012.exchange2012.lab,eTNamespaceName=ActiveDirectory,dc=im,dc=eta
changetype: modify
replace: eTADSDescription
eTADSDescription: 2018-11-19_Thread_Test_by_Alan
dn: eTADSAccountName=testuser testuser,eTADSContainerName=Users,eTADSDirectoryName=dc2012.exchange2012.lab,eTNamespaceName=ActiveDirectory,dc=im,dc=eta
changetype: modify
replace: eTADSDescription
eTADSDescription: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
############################## DXSOAK INPUT FILE ABOVE ########################
5) To force an JCS to become 999.00 in the IMPS Load Balance credits, shut down one of the JCS services.
- net stop im_jcs.
- Monitor the IMPS etatrans*.log Load Balancing message: You will see one of the two (2) JCS servers not being responsive.

6) To watch the JCS rejoin, rename the JCS service
- net start im_jcs
- Suggest using the time CLI to determine when it becomes active.
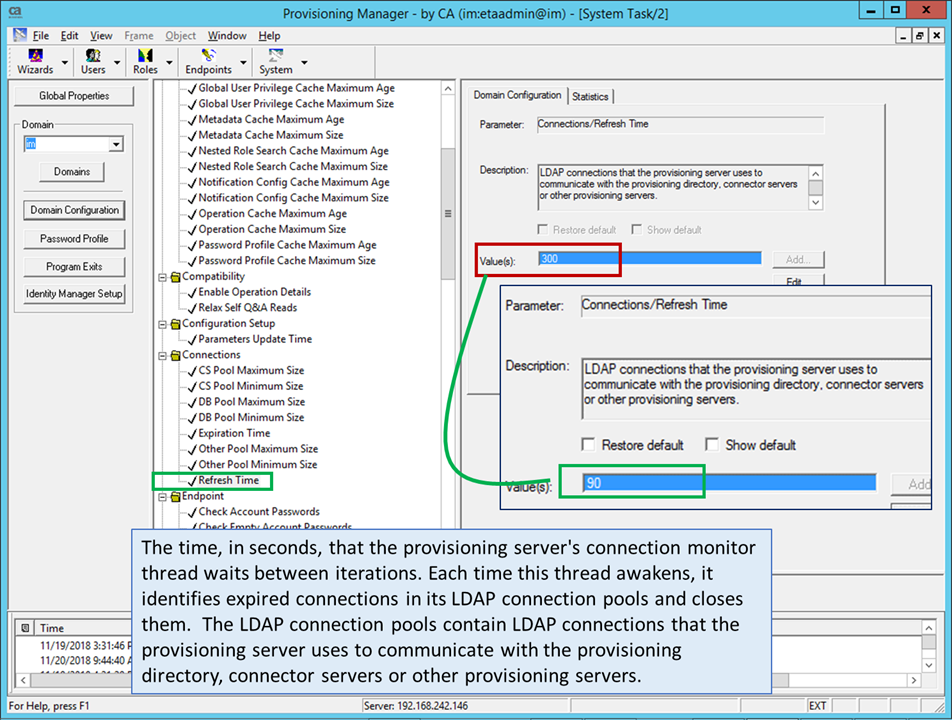
7) Normally, the IMPS service is NOT aware of the status of the JCS, until a OOTB timeout threshold of300 seconds is hit. : IMPS GUI/System/Domain Configuration/ Connections/Refresh Time
- Adjust this refresh timeout to 90 seconds or similar to increase the refresh rate.

8) Now you may observe the IAMCS/CCS load balancing is working as expected.
- NOTE: If you ever note that one of the Load Balancing credits is 999.00 for a longer time than 90 seconds (or 300 seconds), please examine the JCS log (jcs_service_stderr.log) for errors related to the temporary data store of JDBM
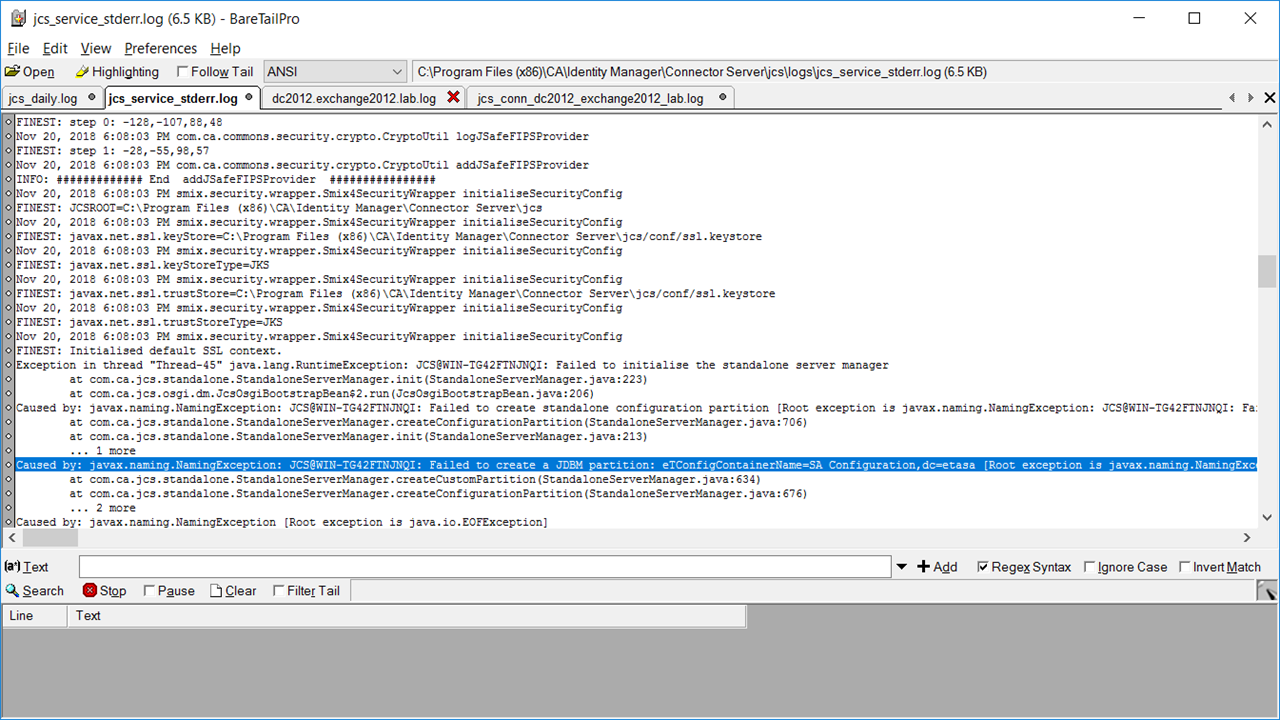
To resolve this issue, stop the im_jcs service, rename the folder jdbm, then restart the JCS service: net start im_jcs. A new JDBM folder will be created, and the JCS service will be fully functional.
- Please review if there was a disk space issue or similar that may have caused this issue to occur.

9) After Load Balancing is validated for the ADS, the extra TEXT logging may be disabled.
Edit: 11/28/2018 negative use-case testing follow-up
10) Negative Use-Case Testing Process:
Exercised negative use-case testing of dropping the JCS service and/or the CCS service independently,
Observation: The JCS service was able to auto-start the CCS service with no issue when there was a single JCS/CCS data stream. A challenge occur with more than one (1) JCS/CCS services. If the CCS service was dropped (net stop im_ccs) to emulate a possible scenario, the JCS appeared to have a challenge restarting the CCS service about 1/2 the time.
I was able to observe that when this occurred, the Load Balance Credits for the data path that was impacted, had a frozen metric, that would not change. This appears to be a good indicator that could be utilized to determine if a data path is impacted, and that it needs investigation, e.g. completely stop / restart the JCS/CCS service to clear out any cache or other issues.
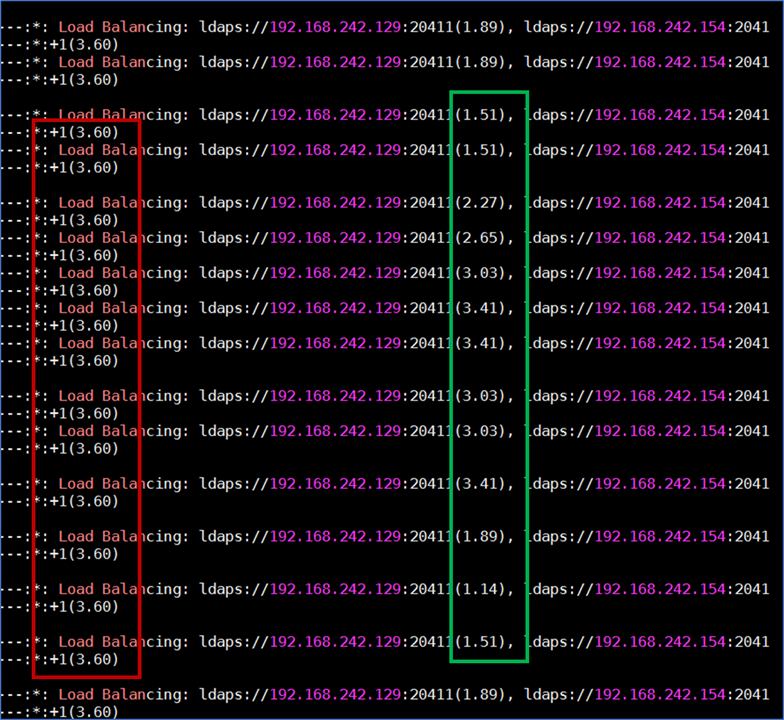
Example: Frozen Load Balance Credits for "bad" JCS, but dynamic Load Balance Credits for working JCS
- Indicate that the CCS service is not responding.
- The IMPS service will still see this as a "good" data path (since it is NOT 999.00) and that any transactions send down this data path, will eventual time out, and then be resent back to the IMPS service, to then re-send back to the JCS servers (where based on round-robin load balancing; it may go down the same "bad" data path)
Action/Recommendation: Monitor the Load Balance Credits (etatrans*.log). Identify any LB Credits that are static for 60-90 seconds; if the value does NOT change (as we would expect the JCS to restart the CCS service to auto-heal), then have a manual or remote service; stop the JCS/CCS service; clear out the logs files (ensure that there is free disk-space), then restart the JCS service & monitor the CCS service does start.
Edit: 12/06/2018 Improve tail process to assist with monitoring; join the "Load Balance" Credits into one line.
One of my customers' top resources, has updated this monitoring process to strip out unneeded characters & is reviewing process to eliminate “false positives” due to when the IMPS servers are not under heavy load, e.g. How long do we wait before we declare the CCS is not responding.
Example: If there is activity, and LB Credits are static, we can easily decide to declare any time > 90 seconds should be addressed; If there is none to little activity, we need to ensure we do not react to little changes as a "false positive" and auto-restart the JCS tier unnecessarily (minimal impact but we would like to avoid).
lfile=`ls -tr /opt/CA/IdentityManager/ProvisioningServer/logs/etatrans*|tail -1`;grep -A1 -h --no-group-separator -i "load balancing" $lfile | cut -d ":" -f 2,8- | sed ':a;N;$!ba;s/\n......:+//g;'|sed 's/ Load Balancing: //;s/ldaps:\/\///g' | less
To test if your current / active etatrans*.log file has any JCS Load Balance Credit messages, parse the above CLI process:
ls -tr /opt/CA/IdentityManager/ProvisioningServer/logs/etatrans* | tail -1 | grep "Load Ba"
or
grep -i "Load Bala" eta*.log
or
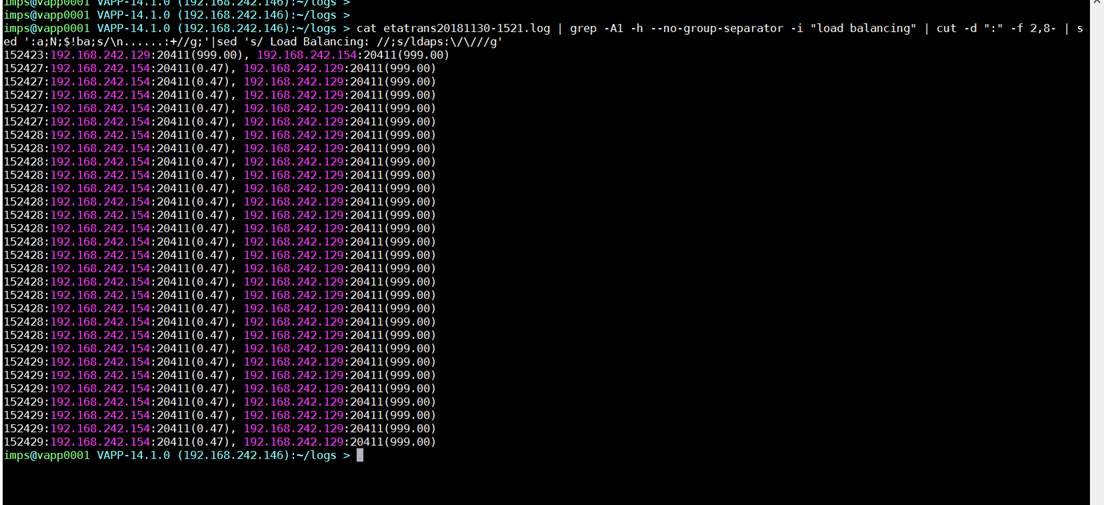
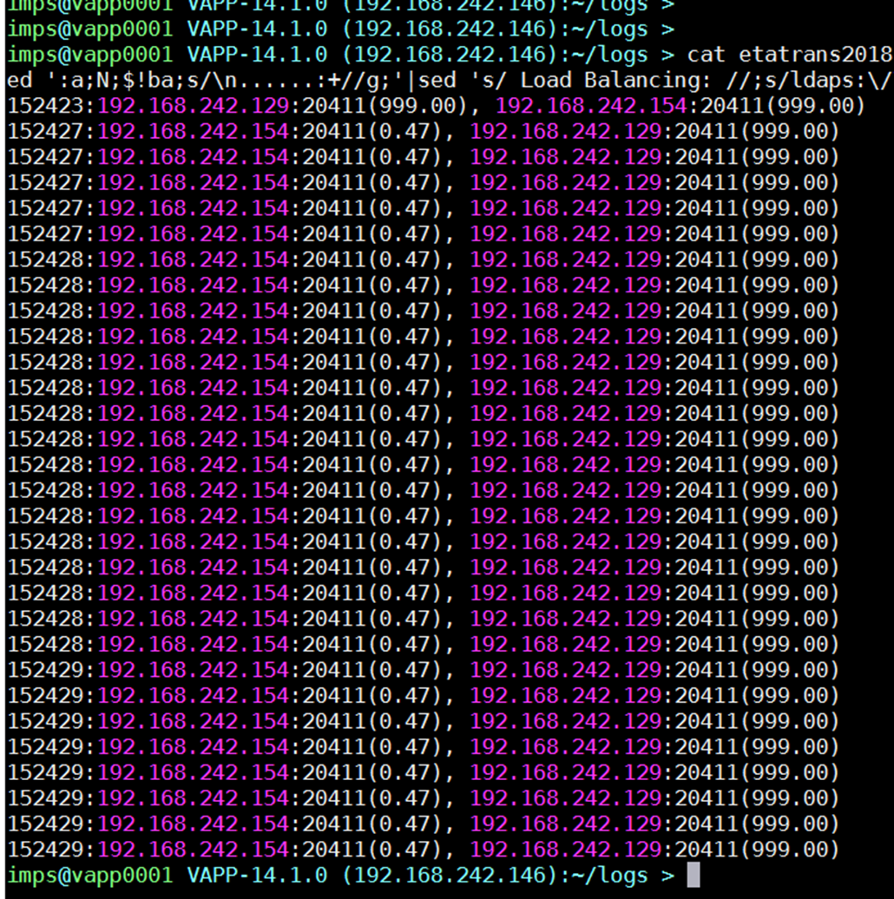
cat etatrans20181130-1521.log | grep -A1 -h --no-group-separator -i "load balancing" | cut -d ":" -f 2,8- | sed ':a;N;$!ba;s/\n......:+//g;'|sed 's/ Load Balancing: //;s/ldaps:\/\///g'
Example below shows one JCS is down (999.00) or non-responsive; and the other JCS (0.47) is either "quiet" or the CCS is non-responsive. For the JCS (0.47) we will need to pre-check that no activity is happening before declaring the CCS is non-responsive (and therefore require a restart of the associated im_jcs service; and avoiding a "false positive").
Cheers,
A.